


A 0-to-60 Intro to Machine Learning
Brand new to machine learning and wondering what it's all about? No problem, dive in and get ready to understand the future of automation.

Machine, noun, often attributive: a mechanically, electrically, or or electronically operated device for performing a task.
Learning, noun: knowledge or skill acquired by instruction or study.
If we were to take these two words, machine and learning, and join them together, we would get two key observations. First, a machine that is able acquire skills by instruction (an algorithm) or study (data). Second, a machine that can use these learned skills to perform a task and thus provide value. At the definition level, this seems quite mundane. But at an implementation level it becomes much more profound.
Programing Today
Let’s first step back and understand how software, via programs (instruction), often get built today by programmers (who have skill). This usually starts when someone has a particular task in mind that they wish to automate:
Customer will input data into a form on a webpage.
This input data is processed by rules (the program) to compute an answer.
The answer is given to the customer.
If we make a diagram, this process would look something like this:
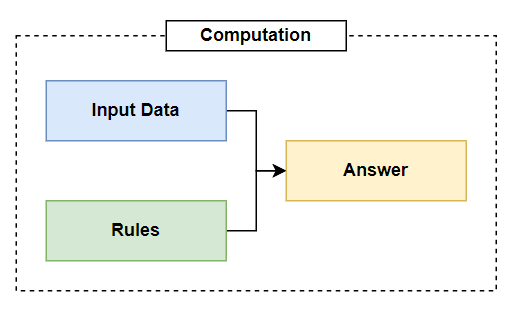
This simple process powers much of the automated digitized world that you interact with today. Sending someone money, buying food with a mobile phone, uploading a picture to a social network; it’s all using input data and rules to produce answers.
The biggest problem with this process is, who creates the rules?
We are living in a world where people are producing lots of new input data. All those picture uploads, dinner orders, and website clicks are collected in a vast databases just waiting to be used for, well, something. But to do that, we would need to build more rules. If every mobile phone user and website clicker is making input data, who is going to build these all rules to make these answers? Well, that would be programmers.
There is a scalability problem here: are there enough skilled programmers that can make rules fast enough to keep up with all the people who are making all this input data? At this point, not a chance. Skilled programmers take decades to train (k-12 included) while software has gotten (arguably) easier to use. As such, we are seeing the volume of input data grow well beyond the capacity of skilled programmers who are able to create rules that could produce quality answers from all of this data.
Machine Learning
Creating the rules has become the bottleneck. This is where machine learning comes in. What if we could give a machine high-level guidance on how it can find patterns in input data so that it could make new rules for us? That would start looking like this:
A machine receives lots of input data (training observations) and separately also receives their answers (training labels).
An algorithm studies these training observations to find patterns (fitting) and tests these patterns by creating an answer (prediction) for each training observation.
These predictions are compared to their training labels (validation). If the predictions are far off, the algorithm restudies the training observations to find a better pattern; if the predictions are accurate, we have effective rules (model).
This continuous process of fitting, prediction, and validation to produce the best model from observations and labels is known as training. When we have our model, we can then input a new observation into it and compute (infer) a new prediction. In this way, we now have an algorithm that can turn data into rules.

Because we are giving the algorithm both the observations (to fit) and labels (to validate) we call this supervised machine learning. We can also train our models without labels in certain circumstances, which would be unsupervised or reinforcement machine learning.
From here, we further break out the type of machine learning algorithm based on the type of prediction we want our model to infer.
Categorical: the prediction represents a specific thing, such as a dog or an application approval. When we use supervised machine learning we call these classification algorithms. When we use unsupervised machine learning we call these clustering algorithms.
Continuous: the prediction represents a measurement, such as a price or an amount of inventory. These mostly use supervised machine learning and we call these regression algorithms.
What’s Next
We’ve discovered something very powerful in all of this. The vast amount of data that businesses are collecting can now be transformed into new programs with far less effort and cost then ever before. Furthermore, many problems can be solved far better with machine learning then conventional programing (such as voice and image recognition), allowing for previously impossible software to now become a reality.
We’ve only scratched the surface here. From deep learning and artificial neural networks to effective model tuning and global-scale deployment, there is still so much more to learn. Subscribe now to never miss a future post from Reactive.BLOG or share with your colleagues so they can learn more too!